Nationwide Diversity and Integration
This notebook pulls together the main features of the censusdis and divintseg projects to demonstrate how quickly and easily we can
Identify US Census data variables.
We will use metadata calls to identify 16 race and ethnicity variables.
Download the variables for the entire country at the block group level.
There are almost 240,000 census block groups in the 50 states and DC.
We will download all 16 variables for all of them.
Compute diversity and integration metrics at the census tract level.
There are over 84,000 census tracts in the 50 states and DC.
Integration expresses how integrated the block groups within a tract are.
Attach geography bounds to all the census tracts.
This process will transparently download and cache census map data on a state by state basis.
censusdiswill determine how to do this and manage the process. No user input is required.
Download state boundaries.
This is simply to make our final maps look better.
Plot maps showing nationwide diversity and integration.
Data is plotted at the census tract level.
Alaska and Hawaii are automatically relocated on the map to better use output real estate.
The state boundaries are plotted to make the maps more readable.
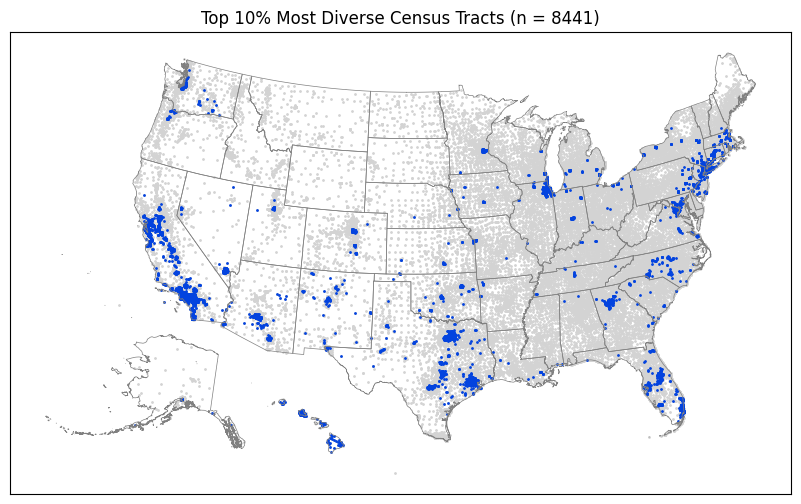
Determine which regions of the country have most concentrated number of the most and least diverse and integrated tracts.
We compute the top and bottom 10% of each metric.
We scatter plot them on maps.
Even in a fresh python environment with no data pre-cached locally, this entire process can be run on a fairly standard laptop with a high-speed internet connection in a just a few minutes.
For more details, please refer to the README files and other documentation in the `censusdis <https://github.com/vengroff/censusdis>`__ and `divintseg <https://github.com/vengroff/divintseg>`__ projects.
0. Imports and configuration
[1]:
# So we can run from within the censusdis project and find the packages we need.
import os
import sys
sys.path.append(
os.path.join(os.path.abspath(os.path.join(os.path.curdir, os.path.pardir)))
)
[2]:
import censusdis.data as ced
import censusdis.maps as cem
from censusdis.states import ALL_STATES_AND_DC
import divintseg as dis
[3]:
# Fill in your own key here, or leave as is
# if you are doing low volume queries that
# will not hit the census server usage limits.
CENSUS_API_KEY = None
1. Identify the dataset and variables we will use
[4]:
DATASET = "acs/acs5"
YEAR = 2020
[5]:
GROUP = "B03002"
2. Download the data
[6]:
%%time
df_bg = ced.download(
DATASET,
YEAR,
leaves_of_group=GROUP,
state=ALL_STATES_AND_DC,
block_group="*",
api_key=CENSUS_API_KEY,
)
CPU times: user 1.91 s, sys: 158 ms, total: 2.07 s
Wall time: 19.2 s
[7]:
df_bg.shape
[7]:
(239780, 20)
3. Compute diversity and integration
[8]:
%%time
df_di = dis.di(
df_bg,
by=["STATE", "COUNTY", "TRACT"],
over="BLOCK_GROUP",
).reset_index()
CPU times: user 1min, sys: 96.1 ms, total: 1min
Wall time: 1min
[9]:
df_di.shape
[9]:
(84414, 5)
4. Infer the geographies so we can plot
[10]:
%%time
gdf_di = ced.add_inferred_geography(df_di, YEAR)
CPU times: user 11.1 s, sys: 160 ms, total: 11.3 s
Wall time: 11.4 s
5. Get state boundaries for the plots
[11]:
%%time
gdf_states = cem.ShapeReader(year=YEAR).read_cb_shapefile("us", "state")
gdf_states = gdf_states[gdf_states.STATEFP.isin(ALL_STATES_AND_DC)]
CPU times: user 297 ms, sys: 4.79 ms, total: 302 ms
Wall time: 301 ms
6. Plot diversity and integration
[12]:
%%time
for col in ["diversity", "integration"]:
ax = cem.plot_us(
gdf_di[gdf_di.geometry != None],
col,
cmap="hot",
legend=True,
figsize=(12, 6),
vmin=0.0,
vmax=1.0,
)
ax = cem.plot_us_boundary(gdf_states, edgecolor="gray", linewidth=0.5, ax=ax)
ax.set_title(col.title())
ax.tick_params(
left=False,
right=False,
bottom=False,
labelleft=False,
labelbottom=False,
)
CPU times: user 18.5 s, sys: 4.25 s, total: 22.7 s
Wall time: 17.9 s
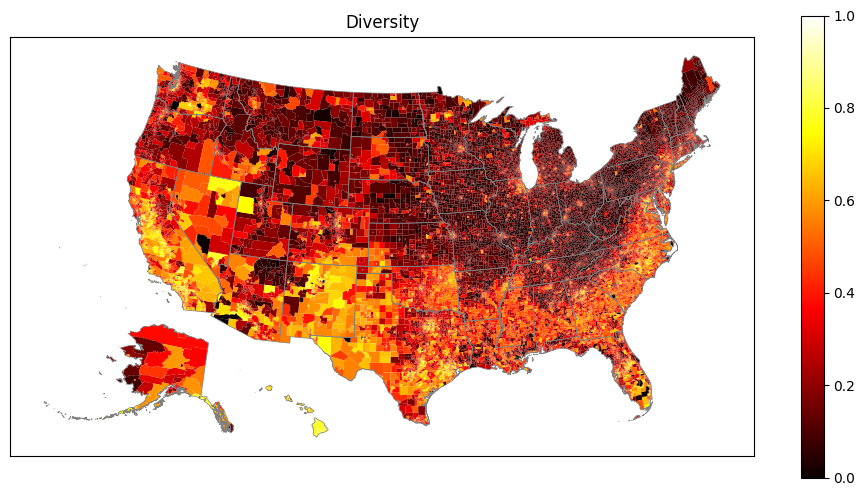
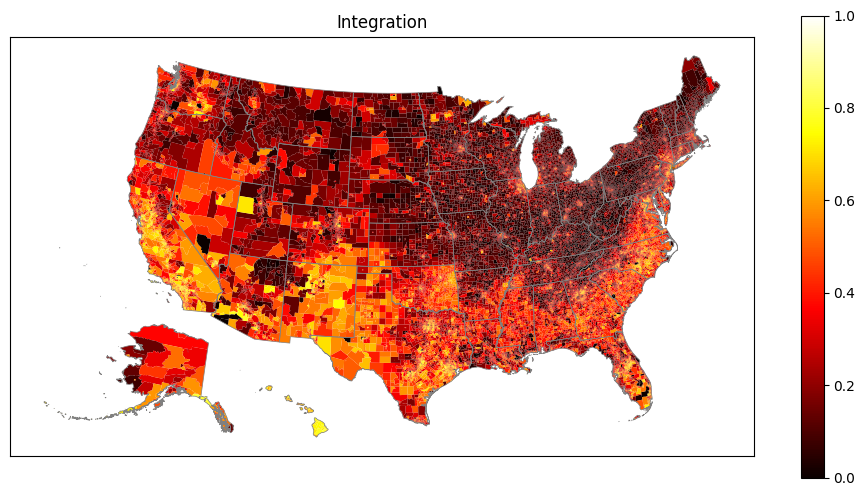
7. What are the top and bottom 10%?
[13]:
%%time
n = len(gdf_di.index)
gdf_di_top_d = gdf_di.nlargest(n // 10, "diversity")
gdf_di_bottom_d = gdf_di.nsmallest(n // 10, "diversity")
gdf_di_top_i = gdf_di.nlargest(n // 10, "integration")
gdf_di_bottom_i = gdf_di.nsmallest(n // 10, "integration")
gdf_di_centroids = gdf_di.copy()
gdf_random_sample = gdf_di.sample(n=n // 10, random_state=17)
CPU times: user 36.6 ms, sys: 3.66 ms, total: 40.3 ms
Wall time: 40.4 ms
[14]:
%%time
# Compute the geometry to centroid points to make the plot
# more readable.
gdf_di_top_d.geometry = cem.geographic_centroids(gdf_di_top_d)
gdf_di_bottom_d.geometry = cem.geographic_centroids(gdf_di_bottom_d)
gdf_di_top_i.geometry = cem.geographic_centroids(gdf_di_top_i)
gdf_di_bottom_i.geometry = cem.geographic_centroids(gdf_di_bottom_i)
gdf_di_centroids.geometry = cem.geographic_centroids(gdf_di_centroids)
gdf_random_sample.geometry = cem.geographic_centroids(gdf_random_sample)
CPU times: user 1.48 s, sys: 77.6 ms, total: 1.56 s
Wall time: 1.55 s
[15]:
def plot_top_or_bottom(
gdf,
metric_description: str,
top_or_bottom: str = "top",
):
"""
A helper plot routine.
Covers most of the repetitive boilerplate that we don't
want to deal with typing more than once.
"""
# Plot configuration.
top_color = "#0343df"
bottom_color = "#E50000"
random_color = "#74216f"
markersize = 1
state_linewidth = 0.5
state_edgecolor = "gray"
all_color = "lightgray"
figsize = (12, 6)
# Actual plotting.
# State bounds
ax = cem.plot_us_boundary(
gdf_states,
edgecolor=state_edgecolor,
linewidth=state_linewidth,
figsize=figsize,
)
# All tracts in a background color
cem.plot_us(
gdf_di_centroids[gdf_di_centroids.geometry != None],
markersize=markersize,
color=all_color,
ax=ax,
)
# The sample we want to emphasize
cem.plot_us(
gdf[gdf.geometry != None],
markersize=markersize,
color=top_color
if top_or_bottom == "top"
else (bottom_color if top_or_bottom == "bottom" else random_color),
ax=ax,
)
if top_or_bottom == "top":
ax.set_title(
f"Top 10% Most {metric_description.title()} Census Tracts (n = {len(gdf.index)})"
)
elif top_or_bottom == "bottom":
ax.set_title(
f"Bottom 10% Least {metric_description.title()} Census Tracts (n = {len(gdf.index)})"
)
else:
ax.set_title(f"Random 10% Sample of Census Tracts (n = {len(gdf.index)})")
ax.tick_params(
left=False,
right=False,
bottom=False,
labelleft=False,
labelbottom=False,
)
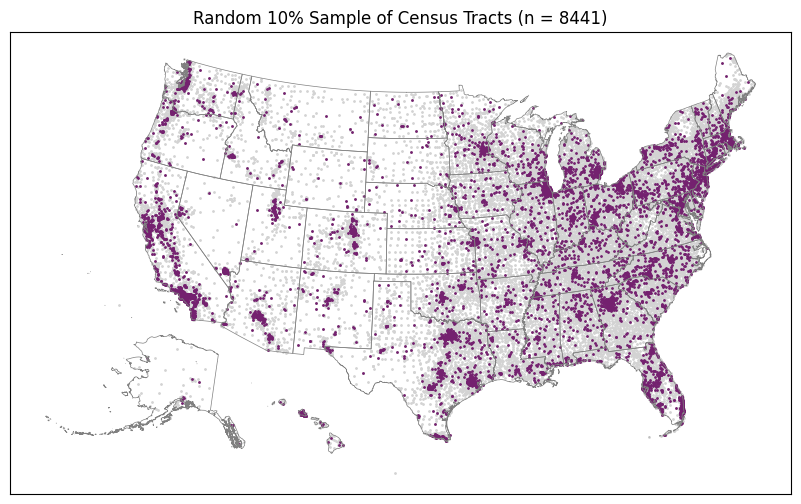
Random 10% Sample
The purpose of this first plot is to show us what the distribution of a random 10% sample looks like. Then we can see if our top and bottom 10% look at all like this or if they are concentrated in regions according to some different kind of spatial distribution.
[16]:
%%time
plot_top_or_bottom(gdf_random_sample, "", top_or_bottom="random")
CPU times: user 3.17 s, sys: 2.03 s, total: 5.2 s
Wall time: 2.31 s
[17]:
%%time
plot_top_or_bottom(gdf_di_top_d, "Diverse")
CPU times: user 3.01 s, sys: 1.93 s, total: 4.94 s
Wall time: 2.2 s
[18]:
%%time
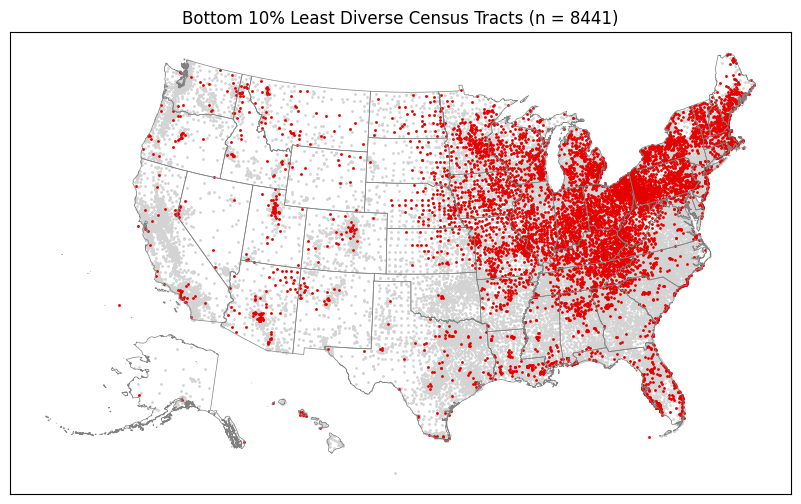
plot_top_or_bottom(gdf_di_bottom_d, "Diverse", top_or_bottom="bottom")
CPU times: user 3.09 s, sys: 1.97 s, total: 5.06 s
Wall time: 2.33 s
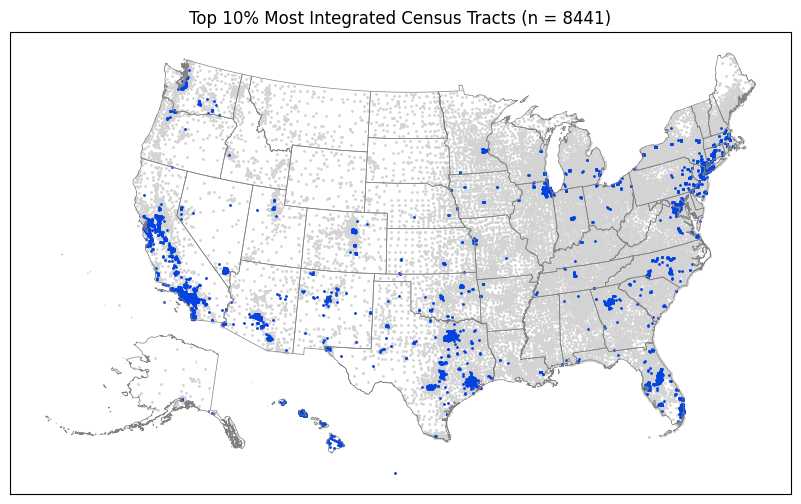
[19]:
%%time
plot_top_or_bottom(gdf_di_top_i, "Integrated")
CPU times: user 3.14 s, sys: 1.9 s, total: 5.04 s
Wall time: 2.19 s
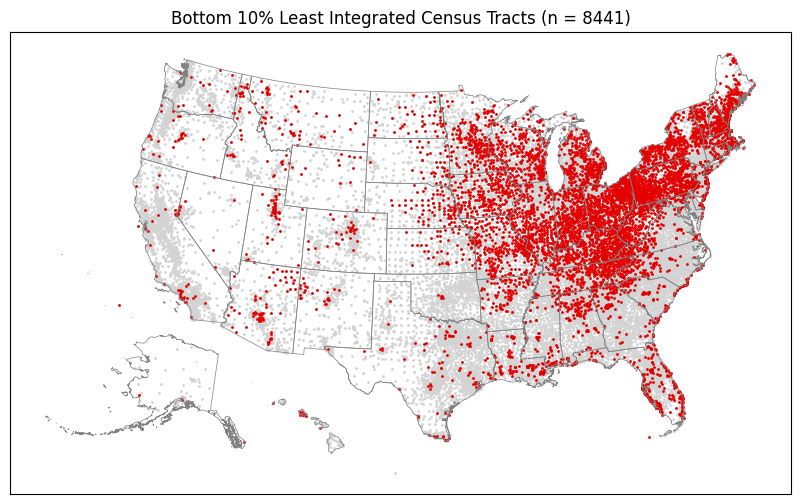
[20]:
%%time
plot_top_or_bottom(gdf_di_bottom_i, "Integrated", top_or_bottom="bottom")
CPU times: user 3.12 s, sys: 2.01 s, total: 5.12 s
Wall time: 2.32 s
[ ]: